解决的问题
对应NLP的任务来说,比如QA、MRC、chatbot等,简单预训练,加上复杂的针对任务的下游网络是否合理?
why
一般针对已经存在的pre-training模型,针对不同的应用有两种策略来应用这种模型:feature based和fine-tuning。两种策略的典型方向对应于:
- feature based: ELMo
- fine-tuning: OpenAI Generative Pre-trained Transformer(GPT)
具体说,ELMo使用预训练的表征作为特定任务的额外特征。而GPT尽可能少地引入任务相关的参数,相反地在具体任务中进行微调。这两种策略在预训练过程中使用相同的目标函数,也就是单向的语言模型来进行学习通用语言的表征。
feature based
ELMo: Deep contextualized word representations
概览
- 解决的问题:
- 表征单词的复杂特性:语法和语义
- 模型的多用型(polysemy)
- 核心
- deep
- function of all internal layers of biLM (bidirectional Language Model)
each token is assigned a representation that is a function of the entire input sentence.
- 发现:
- high-level的LSTM state:语义
- low-level:语法
- 实验:
- textual entailment
- QA
- sentiment analysis
- 比对模型:CoVe (Contextualized word vectors, NIPS-2017)
- 方向:semi-supervised
框架
- 双向语言模型
- as follows:
- $$\sum_{k=1}^{N}(log p(t_k|t_1,…,t_{k-1};\Theta_x,\overrightarrow{\Theta}{LSTM}, \Theta_s) + log p(t_k|t{k+1},…,t_{N};\Theta_x,\overleftarrow{\Theta}_{LSTM}, \Theta_s))$$
- 两个方向上的一些参数会共享
- as follows:
- 核心:
- 对于每一个token $t_k$,L层的biLM计算得到如下的表示:
- $R_k = {x_k^{LM},\overrightarrow{h}_{k,j}^{LM},\overleftarrow{h}^{LM}|j=1,…,L}$
- function:
- $ELMo_k^{task} = E(R_k;\Theta^{task})=\gamma^{task}\sum_{j=0}^Ls_j^{task}h_{k,j}^{LM}$,其中$s^{task}$为归一化的不同层softmax权重
- 对于每一个token $t_k$,L层的biLM计算得到如下的表示:
fine tuning based
Improving Language Understanding with Unsupervised Learning
概览
- 方向:semi-supervised
- 解决的问题:利用大量无标签的数据,进行预训练,再在不同的带有标签的语言任务上进行fine-tune。
- 主要结构:Transformer
- 实验:四种NLU的任务:
- natural language inference
- QA
- semantic similarity
- text classification
- 对之前工作的吐槽:
- 比如Word2vec虽然是基于无标签数据预训练得到,而且也得到了最广泛的应用,但是目前大多数是针对word-level的information transfer,这篇文章的作者目标是捕获更高层次的语义表征
- 传统的手段是通过phrase-level和sentence-level来实现
- 吐槽之前unsupervised用的LSTM,现在用的transformer,可以获取更长范围内的语言结构
- 之前有些工作会利用额外的无监督训练目标函数,作者吐槽虽然他们也用了,但是在无监督预训练中已经可以学到目标任务的相关信息了…
框架
主要分为两个部分:
- 无监督的预训练 (unsupervised pre-training)
- 有监督的微调 (supervised fine-tuning)
无监督预训练
- 给定token:$U = {u_1,…,u_n}$
- 目标函数:$max L_1(U) = \sum_i logP(u_i|u_{i-k},…,u_{i-1};\Theta)$,其中$k$为context window
- 使用了多层Transformer decoder
有监督微调
对于具体任务而言:
- 输入:$x^1, x^2,…,x^m$
- 标签:$y$
- 预训练模块:$M$,假设输入经过该模块的输出为最后一个transformer的$h_l^m$
- 模型输出:$P(y|x^1…x^m) = softmax(h_l^mW_y)$
- 目标函数:$max L_2(C) = \sum_{(x,y)}log P(y|x^1…x^m)$
- 加入无监督训练的目标函数一起优化:$L_3(C) = L_2(C) + \lambda * L_1(C)$
不同任务的修正

what
上述的模型依然无法解决需要为每个特定任务定制各种各种花式的网络结构。BERT的目的便在于此。
BERT
Warm-up
- ELMo: extract context sensitivefeatures from language model
- Transfer Learning from unsupervised data: OpenAI GPT. Pre-train on LM objective, fine-tune on supervised downstream tasks.
- Transfer Learning from supervised data: Need more labeled data.
Architecture
- multi-layer
- bi-directional
- Transformer
总体来说,BERT可以认为是双向transformer结构的LM+fine-tuning结构:
输入
- 目的:同时表征单个文本句子和文本句子对,比如QA中的Q和A

- token embeddings:
- wordpiece embeddings
- CLS for classification problem
- segment embeddings:
- [sep]区分句子
- 添加当前词所在句子的index embedding
- 单个句子,只使用第一个sentence embedding
- position embeddings:
- 当前词偶在位置的index embedding
最后输入为三个embedding的简单相加。。。简单粗暴
核心:预训练模型
- 无监督
- 真正意义上的双向
- 分解为两个任务
Task 1: Masked LM
- 首先想一下目前的双向模型是否是真正的双向?
- 为何目前的双向模型无法真正双向?
解决方案:【Masked Language Model】随机(这里采用15%)覆盖某些token,然后预测这些覆盖的token,而不是像传统LM那样预测下一个词的分布。
有没有问题???
- mismatch between pre-training and fine-tuning,换句话说,[MASK]在fine-tuning的时候未知。
- 训练过程中每个batch只有15%的数据用于预测,预训练模型收敛会变慢。
解决方案:
- 针对15%的token,dataloader分成三个部分:
- 80%情况用[mask]覆盖:
my dog is hairy->my dog is [MASK] - 10%情况用随机单词覆盖:
my dog is hairy->my dog is apple - 10%情况不变:
my dog is hairy->my dog is hairy
- 80%情况用[mask]覆盖:
- 针对15%的token,dataloader分成三个部分:
1 | # get random data in dataloader |
Task 2: Next sentence predition
- 目的:语言模型无法建模句子和句子之间的关系,该task就是为了解决这个问题。
- 语料构建:
- 50%几率替换句子A的下一句话B
- 二分类标签:
isNext和NotNext1
2
3
4
5
6
7def random_sent(self, index):
t1, t2 = self.get_corpus_line(index)
# output_text, label(isNotNext:0, isNext:1)
if random.random() > 0.5:
return t1, t2, 1
else:
return t1, self.get_random_line(), 0
实验
语料
- BookCorpus(800M words)
- English Wikipedia(2,500M words):注意这里尽量使用具有长文本的语料,以此表征长的连续文本关系。
训练
- 超参数:
- batch size:256
- lr:1e-4, learning rate warm-up
- Adam
- L2 decay: 0.01
- dropout: 0.1
- activation: gelu
- 损失函数:
- $loss(task1) + loss(task2)$
计算量
BERT-Base: L = 12, H = 768, A = 12, Total parameters = 110M
BERT-Large: L = 24, H = 1024, A = 16, Total parameters = 340M
其中L表示Transformer层数,H表示Transformer内部维度,A表示Heads的数量
- Base model: 16TPU, 4days
- large model: 64TPU, 4days
- 4 standard GPUs: 99days
如何泛化到不同任务
这里比较了11种不同的NLP任务,具体参考论文。

结果分析
- pre-train model的影响
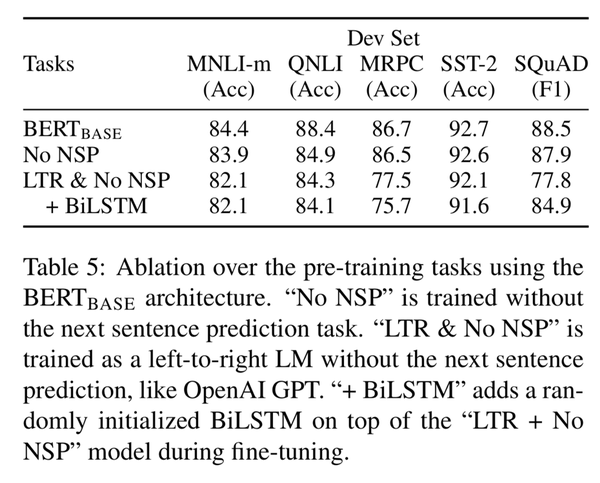
2. training steps的影响
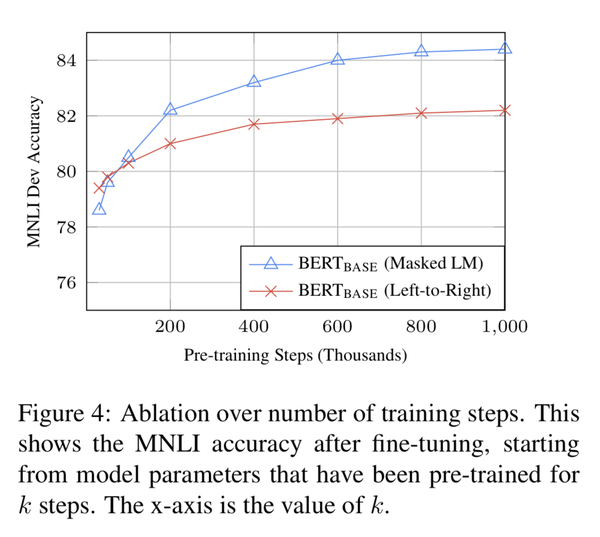
3. BERT+feature-based

how
目前非官方的pytorch实现。
核心模型代码
1 | # model overview |
目前对我们的用处
- character-level word vectors: fasttext in chinese?
- semantic analysis
- entity recognition
- relation extraction: Non-related corpus construction.
- Chinese corpus? wait for model and fine-tune it…
- 对于生成模型是否有帮助(诸如NMT,image captioning)?
- 对于生成模型的benchmark是否有帮助?比如可以根据BERT的结果计算一个metric,然后针对不同任务都有类似的评价指标?
- 该网络是否可以更加简化?
- 和强化学习有和关联或者应用?